PEACH Lab
Built on Open Source
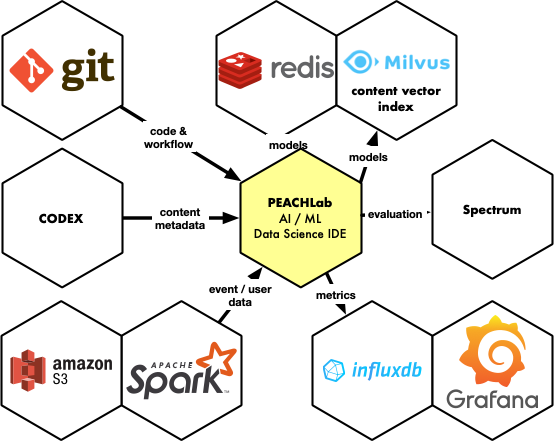
Based on the open-source, industry standards JupyterLab, JupyterHub and Jupyter Notebooks, the PEACH Lab enables data scientist to :
- Explore data collected by the clients from their local computer without the need to install software and dependencies
- Create and refine recommendation models
- Compute business metrics
- Use common (TensorFlow, scikit-learn, pandas, ...) or specific data science and ML libraries.
- Share and track code versions using Git
- Conduct AB testing to measure recommendation performance and improve algorithms
Our additions
We have integrated several additional features on top of Jupyter Lab:
- Access to Redis, the in-memory data structure store, typically used to store metadata, recommendation models and more
- Access to Codex, our metadata repository
- Access to Milvus, the service for a quick vector similarity search
- Definition of Tasks to automate the computation of code. The typical use case is to create/update recommendation models since we have a constant flow of new users, new user data, and newly published content
- Automatic deployment of Recommendation API through the use of a simple declarative configuration file
- Git-based workflow enables data scientists to deploy Tasks and API Recommendation endpoints to production autonomously